OpenAI's GPT-OSS matters. Because it’s …sensible.


There's a particular moment in every technology's lifecycle when the spectacular becomes mundane. When the impossible becomes inevitable. When revolution quietly transforms into infrastructure. Yesterday, OpenAI released GPT-OSS-120B and 20B. Another model. Another breathless press release, though an understated affair relative to the upcoming GPT-5 launch . Another round of LinkedIn updates. But if you listen carefully to what OpenAI actually released - and more importantly, how they released it - you might hear the sound of an industry growing up.
Let's start with what these models actually are, stripped of marketing gloss. GPT-OSS is part of a fascinating evolutionary branch in the AI family tree. Both models employ what's known as mixture-of-experts architecture - a deceptively simple idea that took decades to mature. Imagine, if you will, a hospital emergency room. Not every doctor examines every patient. The cardiologist handles heart issues, the orthopedist manages broken bones, the neurologist addresses head trauma. Efficiency through specialization.
That's MoE in essence. Instead of activating all 117 billion parameters in the larger model, GPT-OSS awakens only 5.1 billion per query - the relevant experts for that particular problem. The smaller model activates just 3.6 billion of its 21 billion parameters. This selective activation isn't just clever engineering; it's economic necessity made elegant. To bring this to life, the diagram below shows the “intelligence” of these models against theory cost of inference - GPT-OSS finds itself firmly in the goldilocks zone of high enough performance, and low enough cost due in large part to this model architecture.
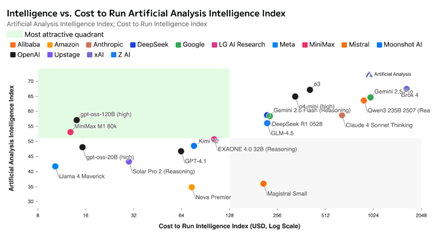
To appreciate how far we've travelled, consider this: Six years ago, OpenAI's GPT-2 shocked the world with 1.5 billion parameters. The company literally refused to release it, fearing its power. Today, that entire model is smaller than a single expert in GPT-OSS's smallest configuration. What once seemed dangerously large is now functionally a rounding error.
But here's where the story takes an unexpected turn. The headline might not really be about the models at all.
Buried in yesterday's announcement was a detail that might reshape the enterprise AI landscape: AWS Bedrock now hosts OpenAI models. For the first time. And hot on the heels of that, these OSS models are now found on the Vertex Model Garden of GCP.
OpenAI has built an ironclad brand, they have become the verb in the AI space the way Photoshop and Google are ubiquitous with editing and search. There is a strong preference for their models and implementations from many business leaders due to this mindshare and the perceived quality of their models despite, as I will show later, the performance gap in the market never being closer. These models don’t provide functionality that others cannot, but they provide a level of brand familiarity and predictability that could be just as important for adoption.
This broader availability then will have several knock-on effects: greater penetration to AI workloads due to the increased utility in different cloud providers, greater utilisation of their standards and APIs and formats like Responses and now Harmony, and what seems like a deepening rift between OpenAI and its historic sponsor – Microsoft. With the news of the $30Bn computing deal with Oracle and likely more to follow, there will come a time, maybe sooner than later, where OpenAI is providing inference on the scale of the major cloud providers. When they release GPT-5/6/7, and upgrading to these new endpoints and increased capability is as easy as changing model routing and billing information, there suddenly exists a swath of new enterprise volume customers for OpenAI. Lock-in via open source?
But the real disruption comes from three words in the technical specifications: "Apache 2.0 license." For those unfamiliar with open-source licensing, Apache 2.0 is the Switzerland of software licenses- neutral, well-understood, and business-friendly. It explicitly permits commercial use, modification, and distribution within proprietary software. No viral clauses. No surprise obligations. No legal gymnastics required. Startup scan build on it without fear. Enterprises can modify it without disclosure. Government scan deploy it without dependency.
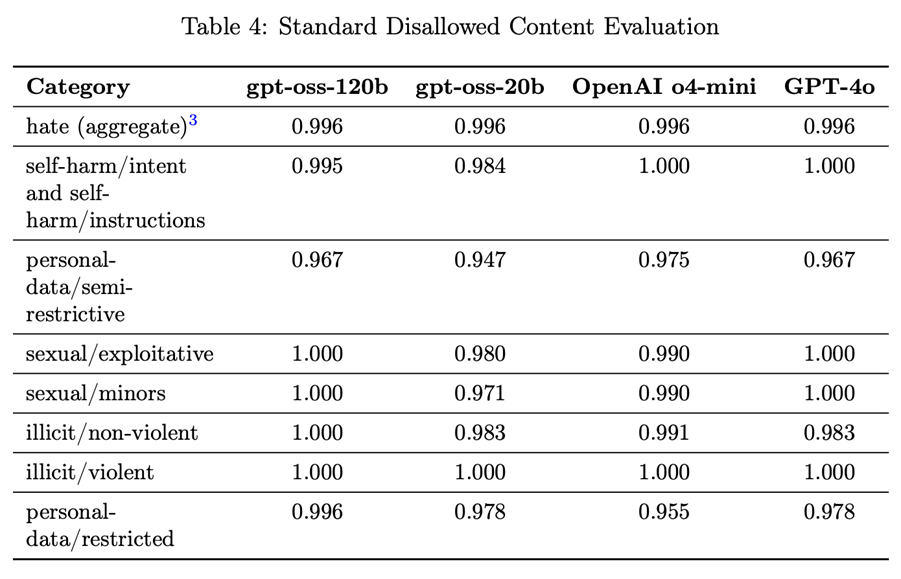
Add to this GPT-OSS's safety profile - OpenAI didn't just test these models; they tried to break them. They fine-tuned adversarial versions, attempting to create the very weapons critics fear. Three independent expert groups reviewed the results. The models proved remarkably resistant to misuse. In our current moment, when a single AI hallucination can destroy a brand overnight, this isn't just responsible development - it's competitive advantage. The following table from their release paper succinctly highlights this - disallowed content is not going to be produced without some serious effort.
Step back from the specifications and benchmarks, and a larger pattern emerges. The winners in the AI race won't be those enterprises who pick the perfect model today. They'll be those that build systems and architectures capable of leveraging whatever comes tomorrow.
Smart organizations are treating AI models like they treat microservice- as interchangeable components in a larger architecture. API gateways that can route to multiple providers. Abstraction layers that hide implementation details. Testing frameworks that can evaluate new models in hours, not months.
This isn't defensive thinking; it's strategic planning. When new models launch weekly, when performance gaps shrink monthly, when costs plummet quarterly, agility becomes more valuable than optimization. The comparative graphs below illustrate this elegantly. If GPT-OSS-120B had been released just last week, the aggregate model intelligence ranking would look like this:
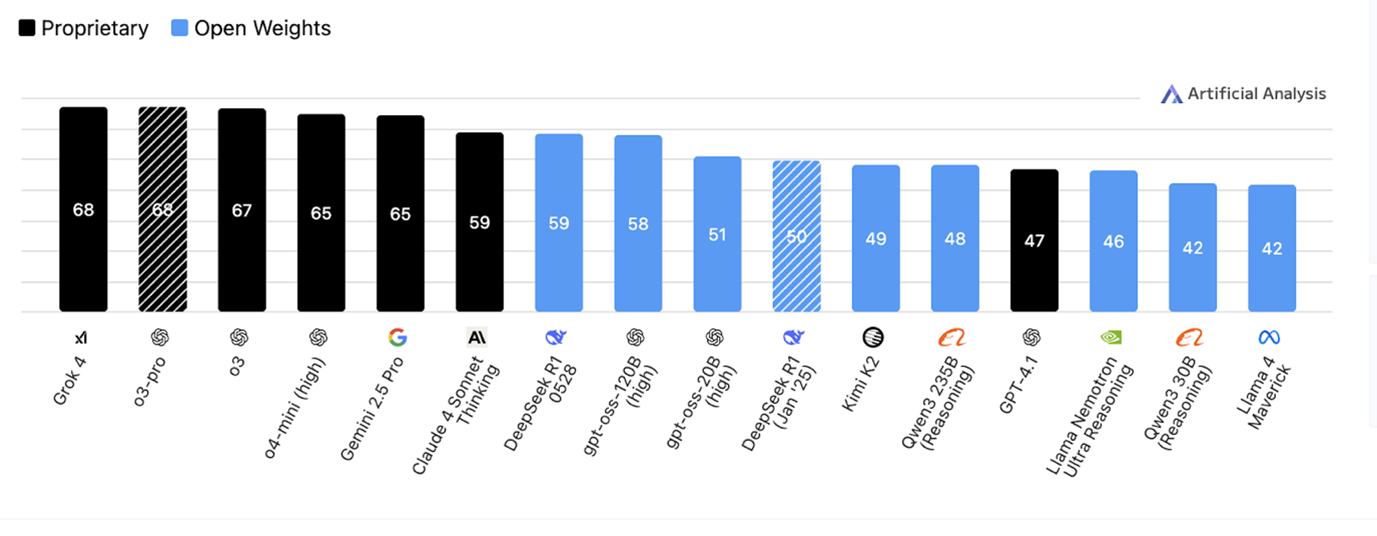
OpenAI find themselves as the second and third strongest open weight model, behind only Deepseek, a model with 5x the number of parameters.
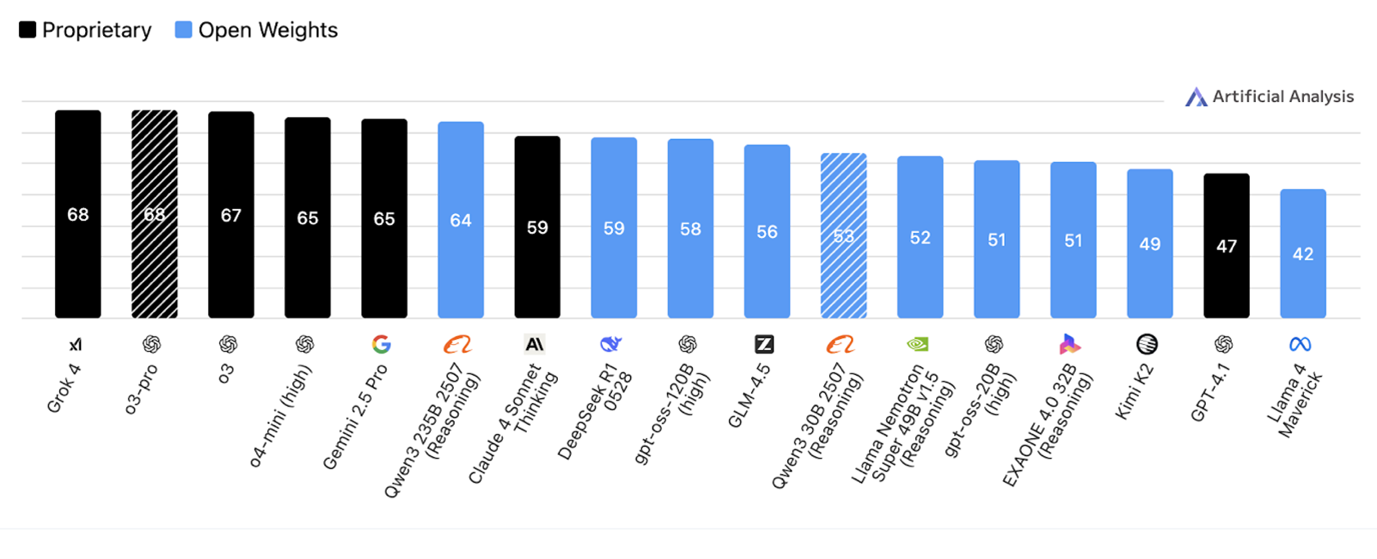
One week later and not only has Qwen released a new model beating even proprietary models, but Nvida, Qwen and Z.ai have all released contenders, knocking the 20B model further down the ranking.
Using open weight models and building in modular, composable architecture strongly supports future-proofed AI services. When the pace of change and improvement is this fast, you can start with one model today and swap it out tomorrow. No architectural debt. Avoid vendor lock-in. No regrets.
Standing here in 2025, watching the AI landscape evolve at breakneck speed, I'm struck by a simple realization: We're past the age of heroes in AI. The era of lone breakthroughs and revolutionary papers is ending. We're entering the age of infrastructure.
GPT-OSS represents this transition perfectly. It's not trying to be GPT-5 or beat Claude at philosophy or match Gemini's multimodal capabilities. It's trying to be useful. Deployable. Reliable. Boring, even. And maybe that's exactly what we need.
The history of technology suggests that the tools that transform society are rarely the most advanced. They're the ones that hit the sweet spot of capability, accessibility, and reliability. The Model T wasn't the best car. The IBM PC wasn't the best computer. The iPhone wasn't the most advanced phone. They are the best designed and the most thoughtful, they're the ones that simply work.
If you’re wondering how to create an AI strategy that's both ambitious and pragmatic—one that positions you to capitalize on rapid innovation while maintaining the stability your business demands, one that simply works, get in touch at https://www.vector8.com/en/contact
Uncover fresh perspectives with our handpicked blog posts on AI advancements.





